


为什么要使用消息队列?(优点)
我觉得使用消息队列主要有三点好处:
- 通过异步处理提高系统性能(减少响应所需时间)。
- 削峰/限流
- 降低系统耦合性。
通过异步处理提高系统性能(减少响应所需时间)
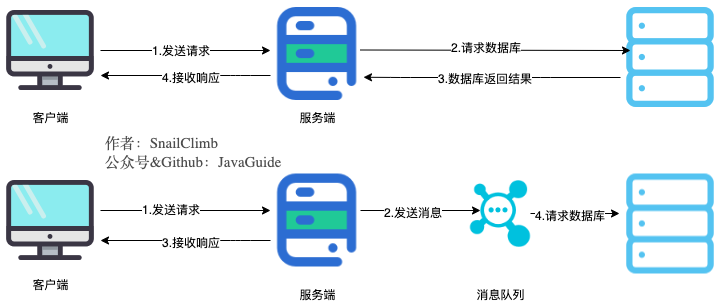
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
因为**用户请求数据写入消息队列之后就立即返回给用户了,**比如注册用户信息可以放到消息队列中,直接给用户返回注册成功。秒杀订单也是如此,放到消息队列后,返回秒杀成功,等待落库后,返回给用户真正的订单信息。
削峰/限流
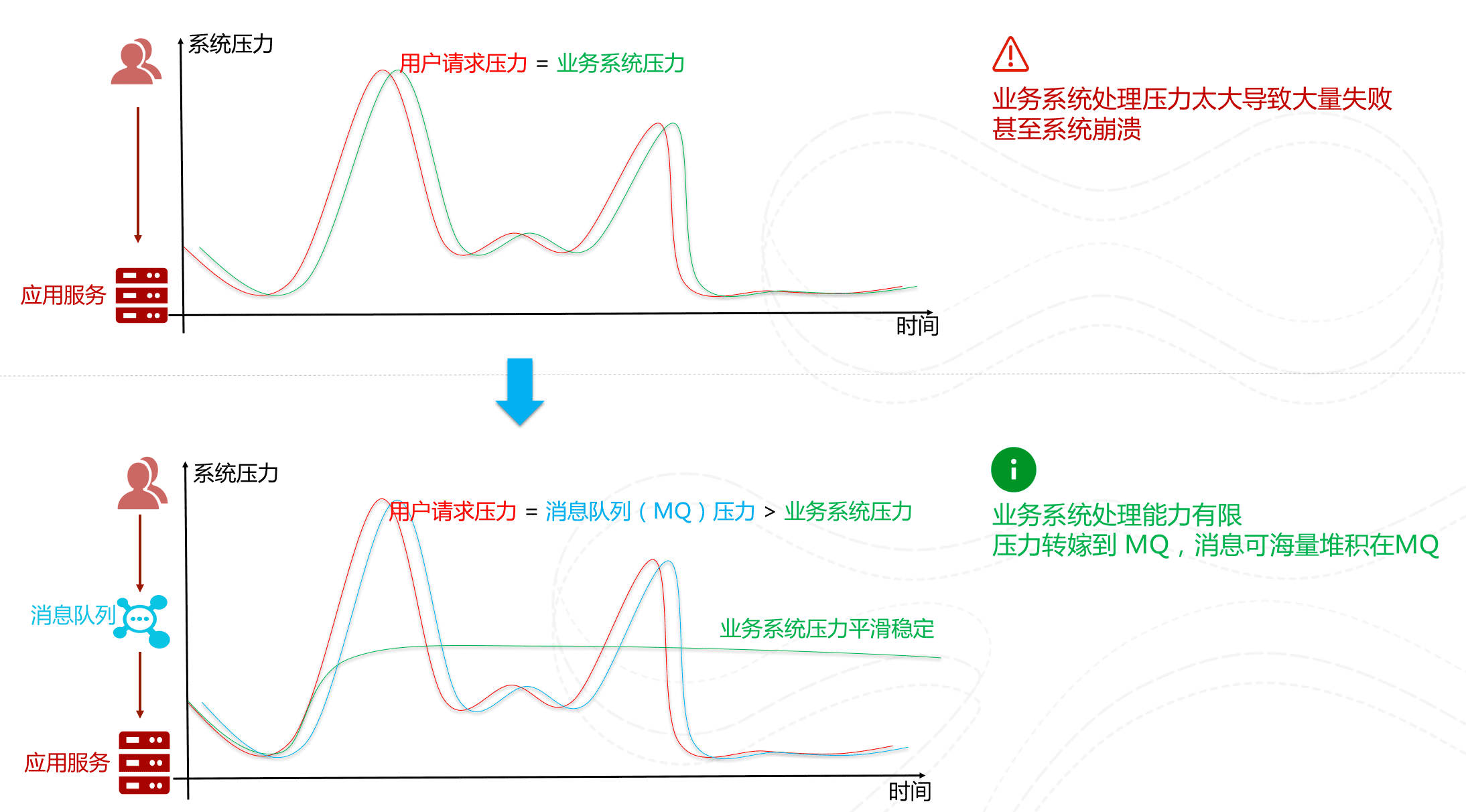
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。
降低系统耦合性
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
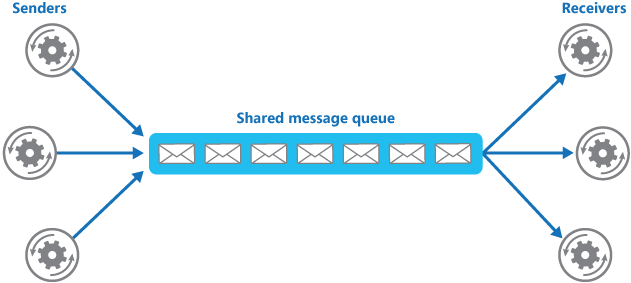
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。 从上图可以看到消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计。
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
备注: 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的。除了发布-订阅模式,还有点对点订阅模式(一个消息只有一个消费者),我们比较常用的是发布-订阅模式。 另外,这两种消息模型是 JMS 提供的,AMQP 协议还提供了 5 种消息模型。
使用消息队列带来的一些问题
- 系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
- 系统复杂性提高: 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
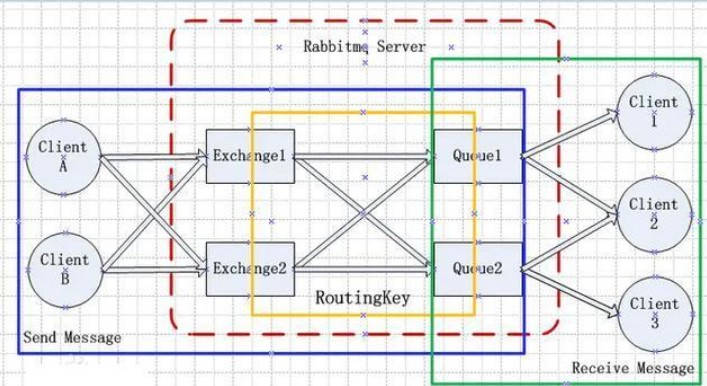
RabbitMQ结构
-
Broker:简单来说就是消息队列服务器实体。
-
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
-
Queue:消息队列载体,每个消息都会被投⼊到⼀个或多个队列。
-
Binding:绑定,它的作⽤就是把exchange和queue按照路由规则绑定起来。
-
Routing Key:路由关键字,exchange根据这个关键字进⾏消息投递。
-
producer:消息⽣产者,就是投递消息的程序。
-
consumer:消息消费者,就是接受消息的程序。
-
channel:消息通道,在客户端的每个连接⾥,可建⽴多个channel,每个channel代表⼀个会话任务。
exchange作用类似于路由器,根据路由键将消息从exchange路由到队列上
exchange有多个种类:direct,fanout,topic
fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。
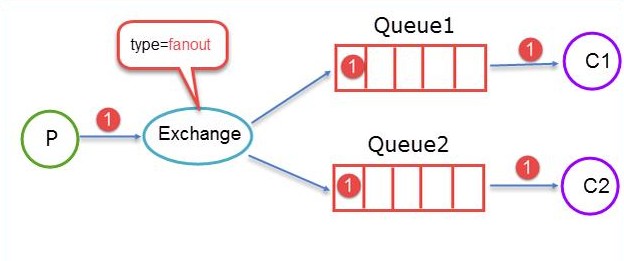
上图所示,生产者(P)生产消息1将消息1推送到Exchange,由于Exchange Type=fanout这时候会遵循fanout的规则将消息推送到所有与它绑定Queue,也就是图上的两个Queue最后两个消费者消费。
direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中
direct图
当生产者(P)发送消息时Rotuing key=booking时,这时候将消息传送给Exchange,Exchange获取到生产者发送过来消息后,会根据自身的规则进行与匹配相应的Queue,这时发现Queue1和Queue2都符合,就会将消息传送给这两个队列;如果我们以Rotuing key=create和Rotuing key=confirm发送消息时,这时消息只会被推送到Queue2队列中,其他Routing Key的消息将会被丢弃。
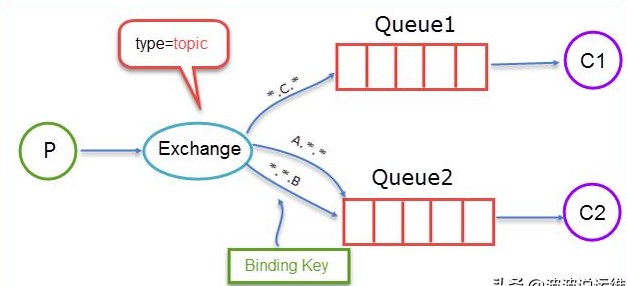
topic
前面提到的direct规则是严格意义上的匹配,换言之Routing Key必须与Binding Key相匹配的时候才将消息传送给Queue,那么topic这个规则就是模糊匹配,可以通过通配符满足一部分规则就可以传送
面试题
1.RabbitMQ怎么防止消息丢失?
消息持久化
RabbitMQ 的消息默认存放在内存上面,如果不特别声明设置,消息不会持久化保存到硬盘上面的,如果节点重启或者意外crash掉,消息就会丢失。
所以就要对消息进行持久化处理。如何持久化,下面具体说明下:
要想做到消息持久化,必须满足以下三个条件,缺一不可。
1) Exchange 设置持久化
2)Queue 设置持久化
3)Message持久化发送:发送消息设置发送模式deliveryMode=2,代表持久化消息
注意,哪怕是你给 RabbitMQ 开启了持久化机制,也有一种可能,就是这个消息写到了 RabbitMQ 中,但是还没来得及持久化到磁盘上,结果不巧,此时 RabbitMQ 挂了,就会导致内存里的一点点数据丢失。
所以,持久化可以跟生产者那边的 confirm 机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者 ack 了,所以哪怕是在持久化到磁盘之前,RabbitMQ 挂了,数据丢了,生产者收不到 ack,你也是可以自己重发的。
ACK确认
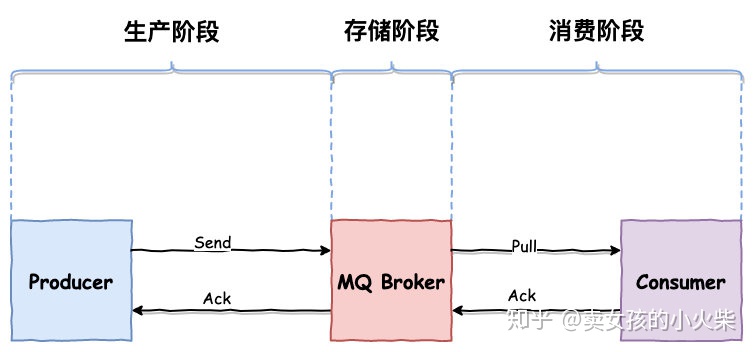
- 生产阶段,Producer 新建消息,然后通过网络将消息投递给 MQ Broker
- 存储阶段,消息将会存储在 Broker 端磁盘中
- 消息阶段, Consumer 将会从 Broker 拉取消息
生产阶段
生产者(Producer) 通过网络发送消息给 Broker,当 Broker 收到之后,将会返回确认响应信息给 Producer。所以生产者只要接收到返回的确认响应,就代表消息在生产阶段未丢失。
存储阶段
默认情况下,消息只要到了 Broker 端,将会优先保存到内存中,然后立刻返回确认响应给生产者。随后 Broker 定期批量的将一组消息从内存异步刷入磁盘。
这种方式减少 I/O 次数,可以取得更好的性能,但是如果发生机器掉电,异常宕机等情况,消息还未及时刷入磁盘,就会出现丢失消息的情况。
若想保证 Broker 端不丢消息,保证消息的可靠性,我们需要将消息保存机制修改为同步刷盘方式,即消息存储磁盘成功,才会返回响应。
修改 Broker 端配置如下:
## 默认情况为 ASYNC_FLUSH flushDiskType = SYNC_FLUSH
若 Broker 未在同步刷盘时间内(默认为 5s)完成刷盘,将会返回 SendStatus.FLUSH_DISK_TIMEOUT 状态给生产者。
集群部署时
为了保证可用性,Broker 通常采用一主(master)多从(slave)部署方式。为了保证消息不丢失,消息还需要复制到 slave 节点。
默认方式下,消息写入 master 成功,就可以返回确认响应给生产者,接着消息将会异步复制到 slave 节点。
注:master 配置:flushDiskType = SYNC_FLUSH
此时若 master 突然宕机且不可恢复,那么还未复制到 slave 的消息将会丢失。
为了进一步提高消息的可靠性,我们可以采用同步的复制方式,master 节点将会同步等待 slave 节点复制完成,才会返回确认响应。
Broker master 节点 同步复制配置如下:
## 默认为 ASYNC_MASTER brokerRole=SYNC_MASTER
如果 slave 节点未在指定时间内同步返回响应,生产者将会收到 SendStatus.FLUSH_SLAVE_TIMEOUT 返回状态。
消费阶段
消费者从 broker 拉取消息,然后执行相应的业务逻辑。一旦执行成功,将会返回 ConsumeConcurrentlyStatus.CONSUME_SUCCESS 状态给 Broker。
如果 Broker 未收到消费确认响应或收到其他状态,消费者下次还会再次拉取到该条消息,进行重试。这样的方式有效避免了消费者消费过程发生异常,或者消息在网络传输中丢失的情况。
2.防止消息重复消费
以redis为例,给消息分配一个全局id,只要消费过该消息,将<id,message>以K-V形式写入redis。那消费者开始消费前,先去redis中查询有没消费记录即可。
评论区